Robots文件内容正确编写教程-推荐收藏
我们在百度站长后,查看百度抓取结果的时候,自己抓取诊断显示正常,但是查看百度自动抓取确会,提示异常或者错误,明明服务器DNS和设置都正常为什么会提示“百度暂时无法连接您的服务器,请检查服务器的设置,确保您网站的服务器能被正常访问。错误码:404或者错误码301或者300等情况”,这就要讲到Robots.txt了,其实是网站上最简单的文件之一,但也是最容易搞乱的文件之一。只要一个字符不合适,就会对您的 SEO 造成严重破坏,并阻止搜索引擎访问您网站上的重要内容。
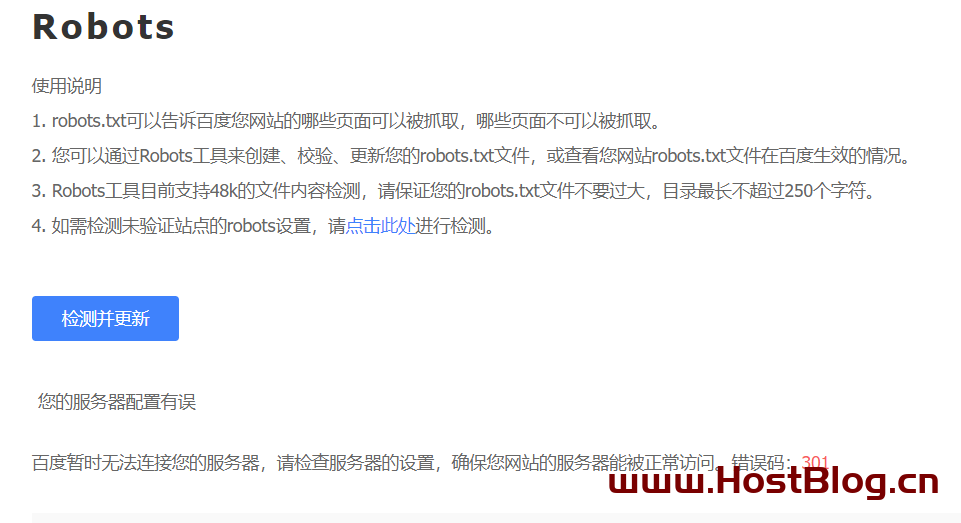
请跟着我的步骤进行一步一步了解,帮你解决这个问题:
一、什么是TXT?
Robots.txt是一个由网站管理者创建并放置于网站根目录下的ASCII编码文本文件。它的主要功能是指导网络搜索引擎的爬虫(也被称为网络蜘蛛)在抓取网站内容时的行为。
二、TXT文件有什么作用?
通过robots.txt文件,网站可以和各大搜索引擎很友好的对话,引导搜索引擎机器人抓取你推荐的网页,避免一些意义不大或无用网页,例如网站后台、会员交互功能等,这在一定程度上也节省服务器网络资源。
三、TXT是什么样的?
Robots.TXT文件的基本格式:
Sitemap: [URL location of sitemap]
User-agent: [bot identifier]
[directive 1]
[directive 2]
[directive ...]
User-agent: [another bot identifier]
[directive 1]
[directive 2]
[directive ...]如果你以前从未看过这些内容,你可能会觉得很难。但实际上,它的语法非常简单。简而言之,你可以通过在文件中指定user-agents(用户代理)和directives(指令)来为搜索引擎蜘蛛分配抓取规则。
让我们详细的讨论则两个组件。
User-agents(用户代理)
每个搜索引擎都有一个特定的用户代理。你可以在robots.txt文件中针对不同的用户代理分配抓取规则。以下是一些对常见的SEO有用的用户代理:
- 谷歌: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- 雅虎: Slurp
- 百度: Baiduspider
- DuckDuckGo: DuckDuckBot
小提示. robots.txt中的所有用户代理均严格区分大小写。
你也可以使用通配符(*)来一次性为所有的用户代理制定规则。
举个例子,假设你想屏蔽除了谷歌以外的搜索引擎蜘蛛,下面就是做法:
#拦截全部蜘蛛
User-agent: *
Disallow: /
#拦截百度蜘蛛
User-agent: Baiduspider
Allow: /四、Robots.TxT文件里面应该怎么写?
“/robots.txt”文件是一个文本文件,包含一条或多条记录。通常包含一条如下所示的记录:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/
在此示例中,排除了三个目录。
请注意,对于要排除的每个 URL 前缀,您需要单独的“Disallow”行 - 您不能在一行上说“Disallow: /cgi-bin/ /tmp/”。此外,记录中不能有空行,因为它们用于分隔多个记录。
另请注意, User-agent 或 Disallow 行中不支持通配符和正则表达式。用户代理字段中的“*”是一个特殊值,表示“任何搜索引擎”。具体来说,您不能使用“User-agent: *bot*”、“Disallow: /tmp/*”或“Disallow: *.gif”等行。
您要排除的内容取决于您的服务器。任何未明确禁止的内容都被视为公平的检索游戏。下面是一些例子:
1、屏蔽所有的搜索引擎收录任何页面
User-agent: * Disallow: /
2、允许所有搜索引擎完全访问收录
User-agent: * Disallow:
或者
User-agent: *
Allow: /(允许所有搜索引擎的方法还有:1、或者只创建一个空的“/robots.txt”文件,2、或者什么都不用创建)
3、从禁止指定的搜索引擎收录
如果只是想有针对性的屏蔽某个或多个搜索引擎,比如禁止百度和谷歌蜘蛛,写法如下。
User-agent: baiduspider Disallow: / User-agent: googelebot Disallow: / User-agent: * Allow: /
4、仅允许指定的搜索引擎收录
需要把搜索引擎蜘蛛的名称写在前面,最后使用*来匹配全部,代码如下。仅允许百度和谷歌收录,其他搜索引擎全部禁止。
User-agent: baiduspider
Allow: /
User-agent: googelebot
Allow: /
User-agent: *
Disallow: /第5、6两句是禁止所有的,前面允许了指定的蜘蛛名称,所以除了被允许的百度和谷歌蜘蛛,其他的搜索引擎都不能收录的网站页面了。
5、排除单个搜索引擎
仅禁止Bing收录
User-agent: BadBot Disallow: /
6、允许单个搜索引擎爬取
仅允许谷歌收录
User-agent: Google Disallow: User-agent: * Disallow: /
7、排除除一个文件之外的所有文件
我们看到,因为没有"Allow"(允许)字段。所以,最简单的方法是将所有不允许的文件放入一个单独的目录中,例如“stuff”,并将一个文件保留在该目录的上一级:
User-agent: * Disallow: /~joe/stuff/
或者,您可以明确禁止所有不允许的页面:
User-agent: * Disallow: /~joe/junk.html Disallow: /~joe/foo.html Disallow: /~joe/bar.html
需要注意的是,在输入的时候一定要严格注意大小写,搜索引擎对这些特别敏感!
五、Robots.TxT文件写好了放置在哪里?
建立Robots.TxT文件夹,输入对应的指令即可,
Robots.TxT文件内容写好后,点击保存,直接放置在根目录即可
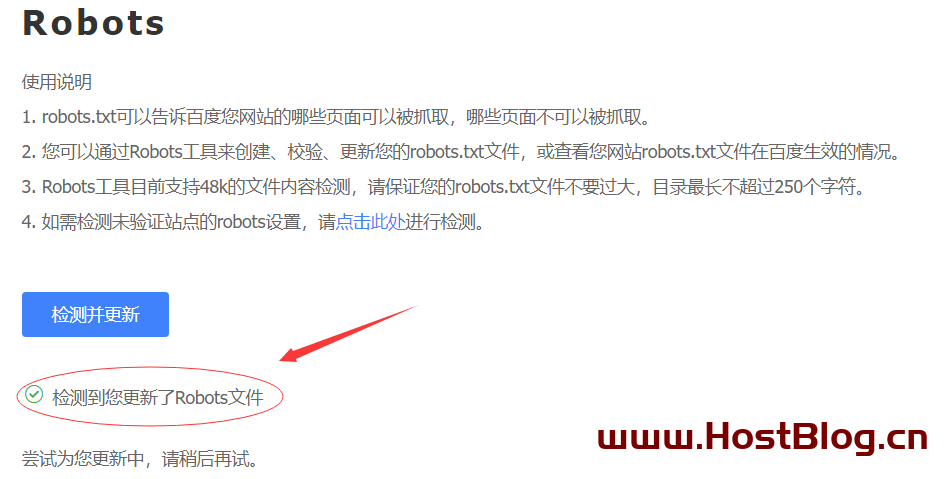
我们再次回到百度Robots检测以下,显示“检测到您更新了Robots文件”

文章作者:主机博客
文章标题:Robots文件内容正确编写教程-推荐收藏
文章地址:https://www.hostblog.cn/547.html
文章版权:
主机博客所发布的内容,部分为原创,转载请注明来源,网络转载文章如有侵权请联系我们!
打赏鼓励:
创作不易,感谢打赏鼓励🙏
