零基础本地部署DeepSeek模型
为什么要本地部署?
- 数据隐私保障:敏感数据无需上传第三方服务器
- 定制化开发:支持模型微调、业务系统集成等深度改造
- 离线环境运行:无网络环境仍可使用AI能力
- 成本可控:长期使用成本低于API调用
注释:以下是本地部署教程,如果您计划在GPU服务器上部署DeepSeek,可以通过下方链接了解本站搜集的高性价比特惠GPU云服务器:https://www.hostblog.cn/2111.html
部署前准备清单
系统要求
要在本地部署DeepSeek模型,需准备Linux(推荐Ubuntu 20.04+)或兼容的Windows/macOS环境,配备NVIDIA GPU(建议RTX 3060+)。安装Python 3.8+、PyTorch/TensorFlow等依赖,并通过官方渠道下载模型文件。
硬件要求
1.GPU:RTX 3060(12GB)
内存:32GB
存储 50GB可用
2.CPU:RTX 3090(24GB)
内存:64GB+
存储 :NVME SSD
软件环境
# 必装组件
conda create -n deepseek python=3.10
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers>=4.33 accelerate sentencepiece
# 验证CUDA可用性
python -c "import torch; print(torch.cuda.is_available())"
模型获取
- 官方渠道下载(需申请权限)
- Hugging Face镜像仓库(推荐):
from huggingface_hub import snapshot_download
snapshot_download(repo_id="deepseek-ai/deepseek-llm-7b-chat")
三步极简部署流程
步骤一:模型初始化
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "./deepseek-llm-7b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16, # 节省显存
device_map="auto" # 自动分配设备
)
步骤二:推理加速配置
# 启用Flash Attention 2加速
model = AutoModelForCausalLM.from_pretrained(
model_path,
use_flash_attention_2=True,
attn_implementation="flash_attention_2"
)
# 8位量化(显存需求降低50%)
model = model.to(torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
))
步骤三:启动API服务
# 快速启动REST API
python -m transformers.serving.run_api \
--model deepseek-llm-7b-chat \
--device cuda:0 \
--port 8000 \
--quantize bitsandbytes # 4位量化模式
验证部署成功
基础测试
prompt = "帮我用Python写一个快速排序算法"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=500)
print(tokenizer.decode(outputs, skip_special_tokens=True))
压力测试脚本
import time
from tqdm import tqdm
test_prompts = [...] # 准备100条测试样本
start_time = time.time()
for prompt in tqdm(test_prompts):
# 执行推理...
print(f"平均响应时间:{(time.time()-start_time)/100:.2f}s")
高阶部署技巧
多卡并行策略
# 手动设备分配
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map={
"transformer.wte": 0,
"transformer.h.0": 0,
"transformer.h.1": 1,
... # 自定义层分配
}
)
# 自动分片(推荐)
model = model.to('cuda')
model = accelerate.dispatch_model(
model,
device_map="auto",
offload_dir="./offload"
)
内存优化方案
- 优化方案 FP32原生
显存占用 100%
推理速度 1x
适用场景 精度敏感任务 - 优化方案 BF16混合精度
显存占用 60%
推理速度 1.1x
适用场景 通用场景 - 优化方案 8-bit量化
显存占用 35%
推理速度 0.95x
适用场景 消费级显卡 - 优化方案 4-bit GPTQ量化
显存占用 18%
推理速度 0.85x
适用场景 显存<12GB的GPU - 优化方案 Flash Attention 2
显存占用 -
推理速度 2.3x
适用场景 长文本生成
常见故障排查
问题1:CUDA out of memory
✅ 解决方案:
- 添加
--max_split_size_mb 128参数 - 尝试
pip install nvidia-cublas-cu12更新驱动
问题2:Tokenizer加载失败
✅ 检查步骤:
- 验证文件完整性:
sha256sum model.safetensors - 确认sentencepiece版本≥0.2.0
问题3:推理结果乱码
✅ 调试方法:
# 检查温度参数
model.generate(..., temperature=0.7, top_p=0.9)
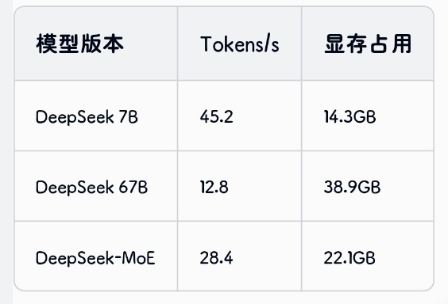
性能对比实测
在RTX 4090上测试结果:

文章作者:主机博客
文章标题:零基础本地部署DeepSeek模型
文章地址:https://www.hostblog.cn/2117.html
文章版权:
主机博客所发布的内容,部分为原创,转载请注明来源,网络转载文章如有侵权请联系我们!
打赏鼓励:
创作不易,感谢打赏鼓励🙏
THE END
